TensorRT の EntropyCalibrator の観察
ディープニューラルネットワーク (DNN) の量子化は、 主に、モデルの Weight と Activation を単精度浮動小数点 (FP32) から 8ビット整数 (INT8) へ 変換することを指す。 この変換は、浮動小数点のスケール $s$ と整数のゼロ点 $z$ を用いて表される。
本稿では、このスケール $s$ の決定のためのキャリブレーションの手法の一つ、 Entropy についてそのアルゴリズムと振る舞いについて書く。
なお、量子化そのものについては、文献 [1] で Quantization Aware Training (QAT) や 8 ビット以下の量子化などを含めた俯瞰的なサーベイが行われている。 また、文献 [2] では、各キャリブレーション手法の評価を含む、実践的な内容が述べられている。
Calibration のアルゴリズム
代表的な Calibration のアルゴリズムとして、以下の 3 種類が挙げられる。[2]
- Max: Calibration において観測された最大の絶対値を使う。
- Entropy: もとの浮動小数点の値と量子化フォーマットで表現できる値の間の情報損失を最小化するために KL-divergence を使う。
- Percentile: Calibration において観測された値の絶対値の分布のパーセンタイルを使う。 例えば、 99% の場合は残りの 1% をクリップする。
なかでも、TensorRT においてデフォルトの手法となっている Entropy についてその振る舞いを理解したい。
Entropy
GTC2017 での NVIDIA による発表資料 [3] をもとに、どのように閾値(スケール)が決定されるかを観察する。
FP32 から INT8 への変換を、再エンコーディングと捉え、その間の情報の損失を最小化することを考える。 2 つのエンコーディングを確率分布と見れば、その2つの確率分布の距離は Kullback-Leibler divergence を用いて表せる。 KL-divergence により、与えられたエンコーディングを近似したときの、情報損失の量を測ることができる。 したがって、情報損失が最小となるような近似を作るのが目的となる。
アルゴリズム
- 入力:アクチベーションのヒストグラム $$ H = [m_0, \ldots, m_{N-1}], N = 2048 $$ を作成する。
- ここから、参照分布 $P$ (
FP32の分布)を生成し、 これとの KL-divergence が最小となるような候補分布 $Q$ (INT8の分布) を見つけることが目的となる。 - そのため、以下の操作を $i= 2^8, \ldots, N$ に渡って繰り返し、 $P, Q$ 間の KL-divergence を計算する。
- まず、参照分布 $P$ を作る。
- $H$ の $i-1$ 番目までのビンを使い、 $$P = [m_0, \ldots, m_{i-1}]$$ とする。
- $H$ の $i$ 以降のビンの合計を計算し、これを外れ値 $O$ とする。 $$O = \sum_{k=i}^{N-1} m_k$$
- 外れ値 $O$ を $P'$ の末尾に足したものを参照分布 $P$ とする。 $$ P(i-1) \leftarrow P(i-1) + O $$
- 次に、候補分布 $Q$ を作る。
- $[m_0, \ldots, m_{i-1}]$ を $2^8$ レベルに量子化する。 つまり、 $i$ 個のビンに分割されたヒストグラムを $2^8$ 個のビンに分割し直す。
- 量子化したヒストグラムを再度 $i$ 個に展開し、 候補分布 $Q$ とする。 このとき、もとのヒストグラム $H$ で $0$ 個であったビンについては、$0$ を保持する。
- $P, Q$ それぞれをその合計で割り、確率分布とする。 $$ P \leftarrow P / \sum{P} $$ $$ Q \leftarrow Q / \sum{Q} $$
- 得られた参照分布 $P$ と候補分布 $Q$ について、KL-divergence を計算する。 $$ KL(P||Q) = \sum_{k=0}^{i-1} P(k) \log\frac{P(k)}{Q(k)} $$
以上から、 $KL(P||Q)$ が最小となる $i$ を求める。
- 最終的な閾値 $\theta$ は、 以下のように求まる。 $$ \theta = (i + 0.5) W $$ ここで、 $W$ はビンの幅。
TensorRT の EntropyCalibrator での振る舞いの観察
公式の実装を参考に、 実際にどのように上記のループが行われるのか観察してみる。
実験設定
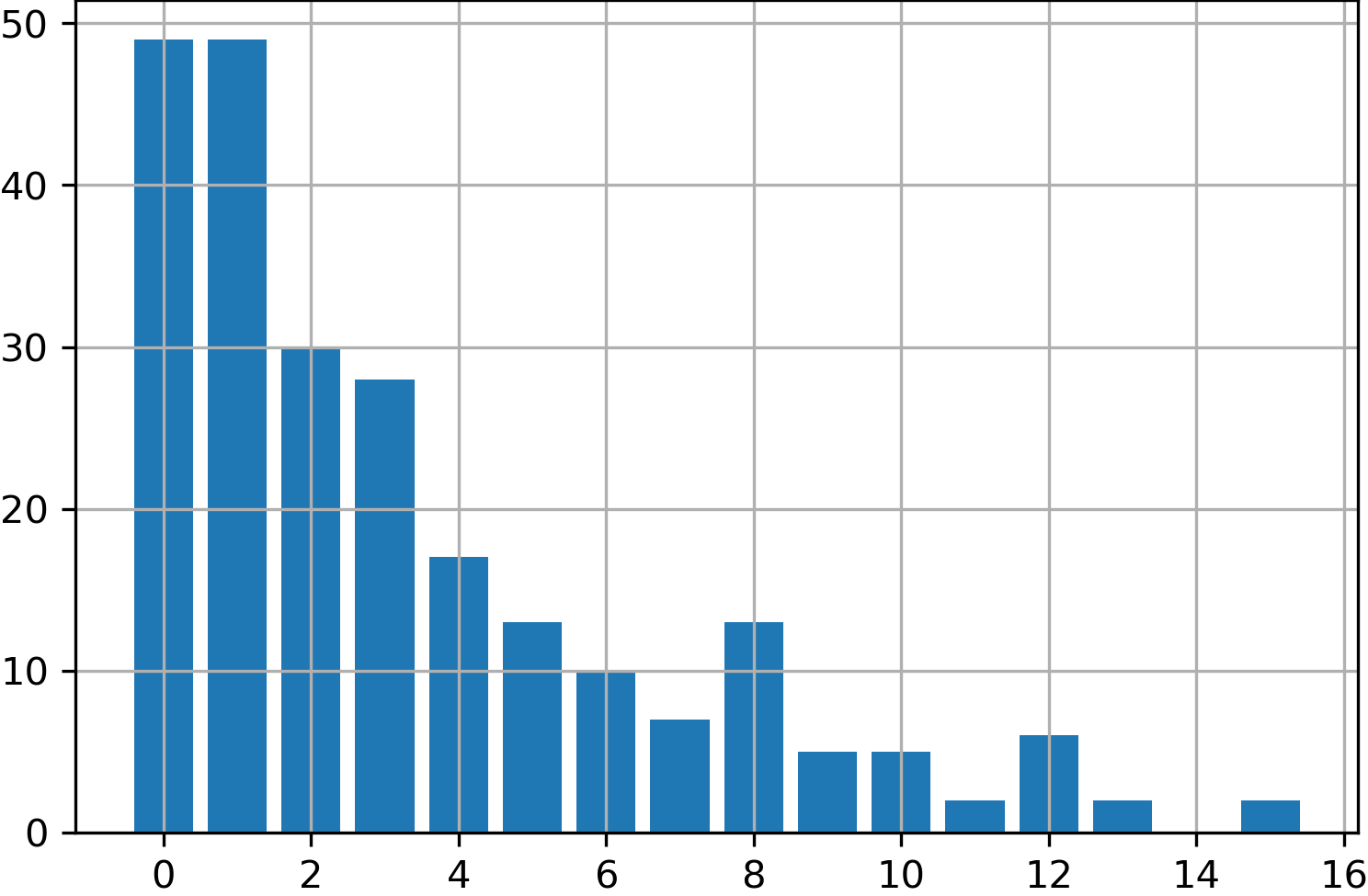
FP32からINT2への量子化を想定し、上のループを実行してみる。- キャリブレーションに用いる
FP32のアクチベーションは、 $\Chi^2$ 分布から生成した $2^8$ 個のランダムな値を用いる。 - 入力のヒストグラム $H$ として、上記を $2^4$ 個のビンに分割したものを用いる(下図)。
結果
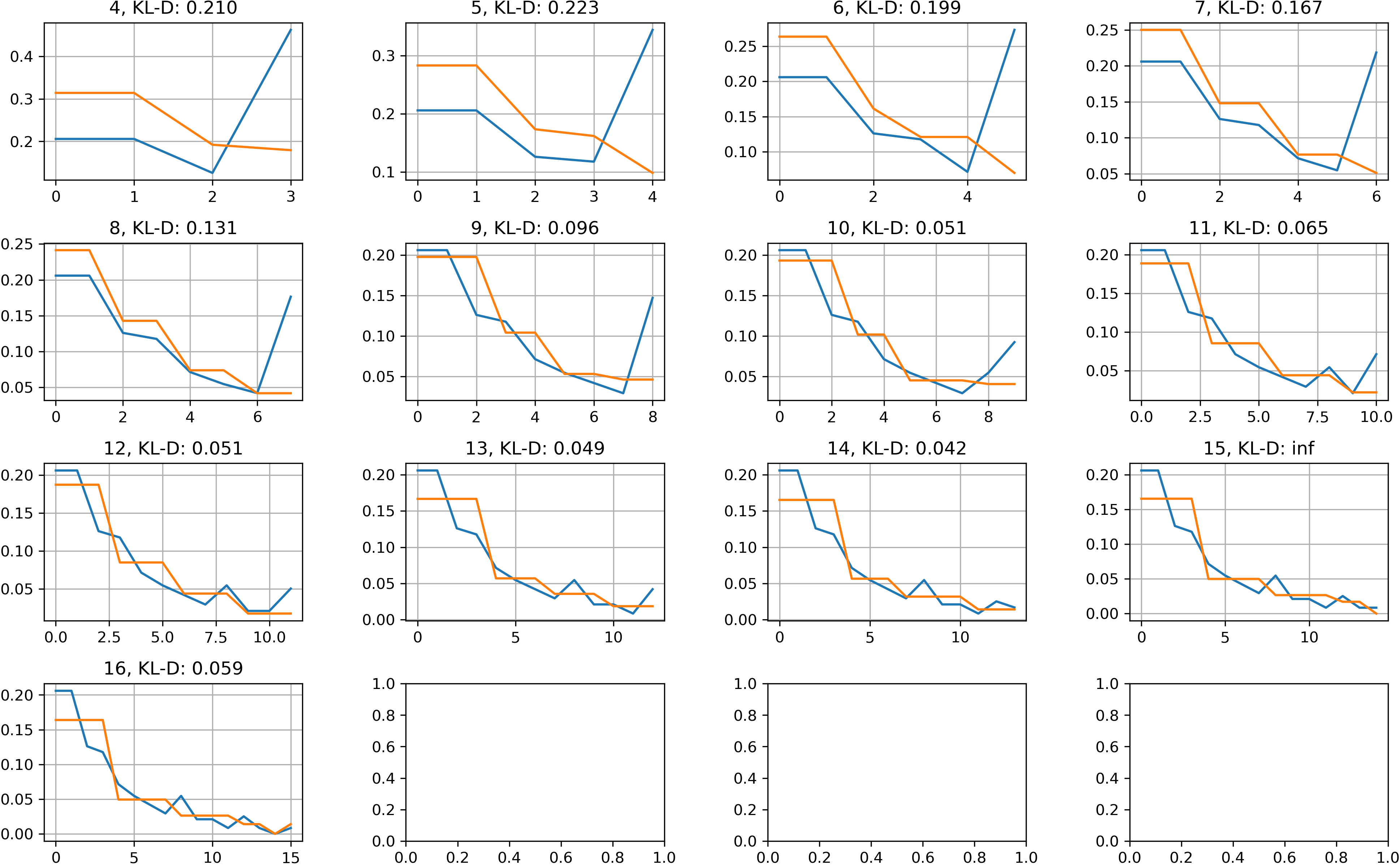
下図に、$i = 2^2, \ldots, 2^4$ について、参照分布 $P$(青)と候補分布 $Q$ (橙)をプロットした。
- 初期は、外れ値 $O$ が大きいため、参照分布 $P$ の末尾の頻度が大きく、 その結果、候補分布 $Q$ との KL-divergence が大きい値となっている。
- $i$ が増加するにつれ、 KL-divergence が小さくなっていく様子が見られるが、 $i=15$ で $\infty$ となっているのが気になる。 KL-divergence の定義から、 KL-divergence が $\infty$ になる場合はあるので、 実運用上問題がないかは検証する必要がありそう。
まとめ
本稿では、 TensorRT での EntropyCalibrator の中身の挙動について アルゴリズムを振り返り、簡単な例での中身の挙動を観察した。
Reference
- [1] Amir Gholami, Sehoon Kim, Zhen Dong, Zhewei Yao, Michael W. Mahoney, Kurt Keutzer. A Survey of Quantization Methods for Efficient Neural Network Inference. arXiv preprint arXiv:2103.13630, 2021.
- [2] Hao Wu, Patrick Judd, Xiaojie Zhang, Mikhail Isaev and Paulius Micikevicius. Integer Quantization for Deep Learning Inference: Principles and Empirical Evaluation. arXiv preprint arXiv:2004.09602, 2020.
- [3] Szymon Migacz. Nvidia 8-bit inference width tensorrt. In GPU Technology Conference, 2017. https://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
- [4] Awesome Model Quantization
- 最新の量子化関連の論文のまとめ