[Reading] Training data-efficient image transformers & distillation through attention
DeiT 論文を読んだのでそのメモ。
多くの ViT 研究において、 DeiT の学習スキームがフォローされている。 最近読んだ ShiftViT1 において言及されており、ちゃんと読んでおこうと思っていた。
書誌情報
@misc{touvron2021training,
title={Training data-efficient image transformers & distillation through attention},
author={Hugo Touvron and Matthieu Cord and Matthijs Douze and Francisco Massa and Alexandre Sablayrolles and Hervé Jégou},
year={2021},
eprint={2012.12877},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
- 図表は特に言及のない限り本論文からの引用。
概要
- ViT と同じネットワーク構造のモデルを用い、学習方法を工夫することで精度を上げ、 また、学習に必要な計算リソース・時間を大きく短縮した。
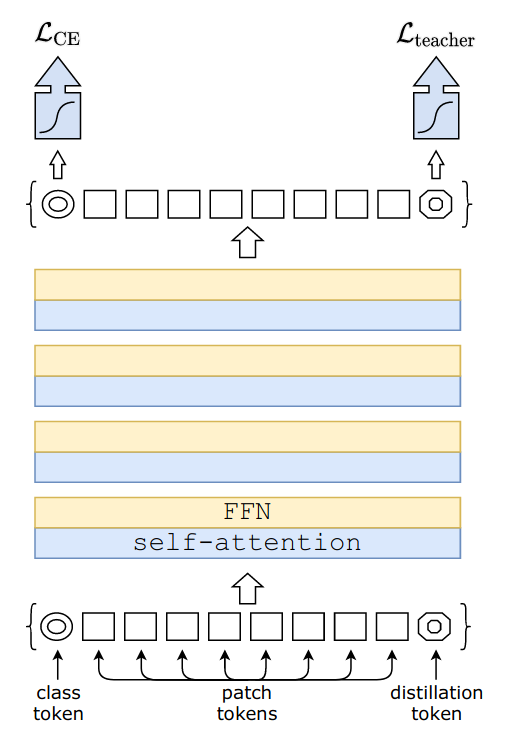
- 蒸留トークン (distillation token) を用いた蒸留手法を提案。 class token とは別の token を用いて 教師モデルからの教師信号を学習させることで、より性能を高められる。
- 学習時の工夫について詳細な分析を行い、よくまとめている。
Distillation
-
Distillation (蒸留) の方法は、 Soft と Hard に大別される。
-
Soft なほうは、生徒モデルの logits $ Z_s $ と 教師モデルの logits $ Z_t $ を KL-loss を使って最小化する。
-
Hard なほうでは、 教師モデルの hard decision $ y_t = \argmax_c Z_t(c) $ を使い、 Cross entropy で最適化する。
- この方法は Soft と異なりパラメータフリーであるという良さがある。
- さらに実験では label smoothing と呼ばれる手法を取り入れている。 すなわち、 真なクラスを $ 1 - \epsilon $ とし、その他のクラスを $\epsilon$ で等分するといった方法である。
-
-
蒸留トークン (distillation token)
- クラストークンとは別に、 蒸留トークンを加える。
- 蒸留トークンもクラストークンと同様に使うが、 クラストークンと異なり、 こちらは教師モデルの hard decision を教師信号とする。
- クラストークンと蒸留トークンは同じような出力をするが、全く同じではない。
実験結果より、
- 蒸留トークンを使わない場合、3 種類の蒸留手法 (行わない/ソフト/ハード) のうち ハードが最も良かった。
- 蒸留トークンを使用し、 ハード蒸留を使って学習を行った後、 クラス予測には、クラス embedding, 蒸留 embedding, 両方の3種類の方法を使うことが考えられる。 このうち最も結果がよかったのは、 蒸留 embedding を使うもので、 これは、教師モデルである convnet の帰納バイアスの恩恵を受けているからだろうと著者は考えている。
学習戦略に関する ablation study
重みの初期化
Transformer は比較的初期化方法に敏感であり、方法によっては収束しない場合がある。 最終的に切断正規分布 (truncated normal distribution) を使用して重みの初期化を行った。
data augmentation
- Transformer では convolution に比べより多くのデータ量が必要。
- convolution はより多くの事前分布を統合することができる。
- 同じ大きさのデータセットで学習を行うためには、大規模な data augmentation を 行う必要がある。
- データ効率の良い学習を行うために、異なるタイプの強力な data augmentation を評価。
- Auto-augment, rand-augment, random erasing により性能が向上。
- ほとんどの data augm. 手法は有用であることが分かった。
正則化と最適化
- 最適化アルゴリズム
- ViT と同じく AdamW を用い、学習率を同じ値を用いることが最も良い結果となった。
- ただし、 Weight Decay の値は、収束のためにより小さい値を用いることとした。
- Stochastic depth
- Dropout は ノードをオフにする = 横方向にネットワークを小さくする。
- Stochastic depth は Layer 数を変化させる = 縦方向にネットワークを小さくする。
- Short なネットワークを学習し、 Deep なネットワークを得ることができる。
- 特に深い transformer の収束を促進させる。
- 正則化
- Mixup
- Cutmix
- repeated augmentation
- 一つの画像からいくつかの augmentation 画像をつくることで、 1 バッチ内で同じサンプルを複数回読み込ませる手法。
- 提案した学習スキームの鍵となる構成要素。
Exponential Moving Average (EMA)
- EMA を行うことで、0.1 pt 程度性能が向上したが、 fine tuning すると、同じ結果となった。
異なる解像度での fine tuning
- 学習は解像度は 224 で行ったが、 fine-tuning は 384 で行った。
- Fixing the train-test resolution discrepancy
- 学習時の解像度は、テスト時より小さい解像度のほうが良いという先行研究。
- FixefficientNet と異なり、学習時の augmentation は弱めずに行う。
- Positional embeddings の補間
- bilinear ではなく、 bicubic を用いて補間を行った。
- bilinear を用いると、その補間された verctor の $ l_2 $ ノルムが 隣接する vector のノルムよりも小さくなってしまう。
- これを fine-tuning せずに Transformer に適用すると、性能が著しく落ちる。
- bicubic を用いると、vector の norm が維持される。
学習時間
- batch norm を使っていないので、 batch size を減らしても性能に影響しない。 よって、大きなモデルを学習するのが簡単になる。
参照
- https://zenn.dev/takoroy/scraps/ced7059a36d846
- takoroy さんによる本論文のメモ。
- https://qiita.com/supersaiakujin/items/eb0553a1ef1d46bd03fa
- stochastic depth について、 supersaiakujin さんによる記事。